Troubleshooting Geo (PREMIUM SELF)
Setting up Geo requires careful attention to details, and sometimes it's easy to miss a step.
Here is a list of steps you should take to attempt to fix problem:
- Perform basic troubleshooting.
- Fix any PostgreSQL database replication errors.
- Fix any common errors.
- Fix any non-PostgreSQL replication failures.
Basic troubleshooting
Before attempting more advanced troubleshooting:
Check the health of the Geo sites
On the primary site:
- On the left sidebar, at the bottom, select Admin Area.
- Select Geo > Sites.
We perform the following health checks on each secondary site to help identify if something is wrong:
- Is the site running?
- Is the secondary site's database configured for streaming replication?
- Is the secondary site's tracking database configured?
- Is the secondary site's tracking database connected?
- Is the secondary site's tracking database up-to-date?
- Is the secondary site's status less than 10 minutes old?
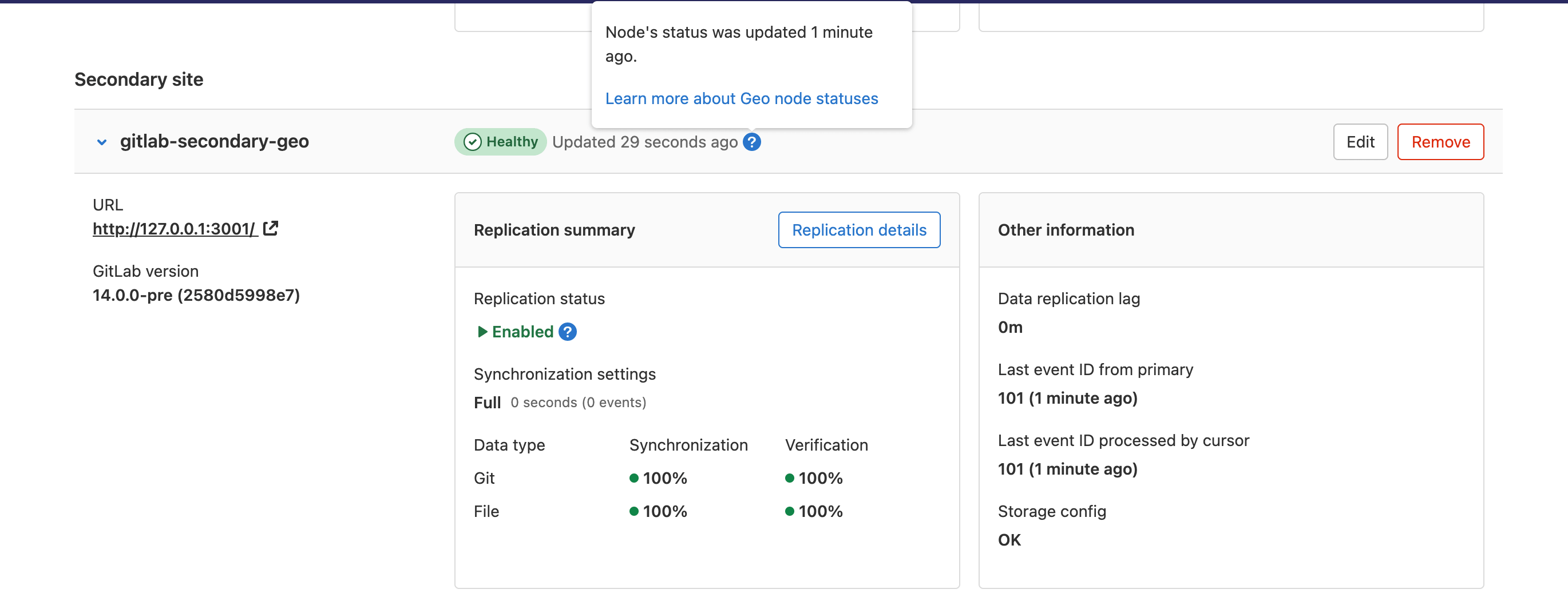
A site shows as "Unhealthy" if the site's status is more than 10 minutes old. In that case, try running the following in the Rails console on the affected secondary site:
Geo::MetricsUpdateWorker.new.performIf it raises an error, then the error is probably also preventing the jobs from completing. If it takes longer than 10 minutes, then there may be a performance issue, and the UI may always show "Unhealthy" even if the status eventually does get updated.
If it successfully updates the status, then something may be wrong with Sidekiq. Is it running? Do the logs show errors? This job is supposed to be enqueued every minute and might not run if a job deduplication idempotency key was not cleared properly. It takes an exclusive lease in Redis to ensure that only one of these jobs can run at a time. The primary site updates its status directly in the PostgreSQL database. Secondary sites send an HTTP Post request to the primary site with their status data.
A site also shows as "Unhealthy" if certain health checks fail. You can reveal the failure by running the following in the Rails console on the affected secondary site:
Gitlab::Geo::HealthCheck.new.perform_checksIf it returns "" (an empty string) or "Healthy", then the checks succeeded. If it returns anything else, then the message should explain what failed, or show the exception message.
For information about how to resolve common error messages reported from the user interface, see Fixing Common Errors.
If the user interface is not working, or you are unable to sign in, you can run the Geo health check manually to get this information and a few more details.
Health check Rake task
The use of a custom NTP server was introduced in GitLab 15.7.
This Rake task can be run on a Rails node in the primary or secondary Geo sites:
sudo gitlab-rake gitlab:geo:checkExample output:
Checking Geo ...
GitLab Geo is available ... yes
GitLab Geo is enabled ... yes
This machine's Geo node name matches a database record ... yes, found a secondary node named "Shanghai"
GitLab Geo tracking database is correctly configured ... yes
Database replication enabled? ... yes
Database replication working? ... yes
GitLab Geo HTTP(S) connectivity ...
* Can connect to the primary node ... yes
HTTP/HTTPS repository cloning is enabled ... yes
Machine clock is synchronized ... yes
Git user has default SSH configuration? ... yes
OpenSSH configured to use AuthorizedKeysCommand ... yes
GitLab configured to disable writing to authorized_keys file ... yes
GitLab configured to store new projects in hashed storage? ... yes
All projects are in hashed storage? ... yes
Checking Geo ... FinishedYou can also specify a custom NTP server using environment variables. For example:
sudo gitlab-rake gitlab:geo:check NTP_HOST="ntp.ubuntu.com" NTP_TIMEOUT="30"The following environment variables are supported.
| Variable | Description | Default value |
|---|---|---|
NTP_HOST |
The NTP host. | pool.ntp.org |
NTP_PORT |
The NTP port the host listens on. | ntp |
NTP_TIMEOUT |
The NTP timeout in seconds. | The value defined in the net-ntp Ruby library (60 seconds). |
If the Rake task skips the OpenSSH configured to use AuthorizedKeysCommand check, the
following output displays:
OpenSSH configured to use AuthorizedKeysCommand ... skipped
Reason:
Cannot access OpenSSH configuration file
Try fixing it:
This is expected if you are using SELinux. You may want to check configuration manually
For more information see:
doc/administration/operations/fast_ssh_key_lookup.mdThis issue may occur if:
- You use SELinux.
- You don't use SELinux, and the
gituser cannot access the OpenSSH configuration file due to restricted file permissions.
In the latter case, the following output shows that only the root user can read this file:
sudo stat -c '%G:%U %A %a %n' /etc/ssh/sshd_config
root:root -rw------- 600 /etc/ssh/sshd_configTo allow the git user to read the OpenSSH configuration file, without changing the file owner or permissions, use acl:
sudo setfacl -m u:git:r /etc/ssh/sshd_configSync status Rake task
Current sync information can be found manually by running this Rake task on any node running Rails (Puma, Sidekiq, or Geo Log Cursor) on the Geo secondary site.
GitLab does not verify objects that are stored in Object Storage. If you are using Object Storage, you will see all of the "verified" checks showing 0 successes. This is expected and not a cause for concern.
sudo gitlab-rake geo:statusThe output includes:
- a count of "failed" items if any failures occurred
- the percentage of "succeeded" items, relative to the "total"
Example:
http://secondary.example.com/
-----------------------------------------------------
GitLab Version: 14.9.2-ee
Geo Role: Secondary
Health Status: Healthy
Project Repositories: succeeded 12345 / total 12345 (100%)
Project Wiki Repositories: succeeded 6789 / total 6789 (100%)
Attachments: succeeded 4 / total 4 (100%)
CI job artifacts: succeeded 0 / total 0 (0%)
Design management repositories: succeeded 1 / total 1 (100%)
LFS Objects: failed 1 / succeeded 2 / total 3 (67%)
Merge Request Diffs: succeeded 0 / total 0 (0%)
Package Files: failed 1 / succeeded 2 / total 3 (67%)
Terraform State Versions: failed 1 / succeeded 2 / total 3 (67%)
Snippet Repositories: failed 1 / succeeded 2 / total 3 (67%)
Group Wiki Repositories: succeeded 4 / total 4 (100%)
Pipeline Artifacts: failed 3 / succeeded 0 / total 3 (0%)
Pages Deployments: succeeded 0 / total 0 (0%)
Repositories Checked: failed 5 / succeeded 0 / total 5 (0%)
Package Files Verified: succeeded 0 / total 10 (0%)
Terraform State Versions Verified: succeeded 0 / total 10 (0%)
Snippet Repositories Verified: succeeded 99 / total 100 (99%)
Pipeline Artifacts Verified: succeeded 0 / total 10 (0%)
Project Repositories Verified: succeeded 12345 / total 12345 (100%)
Project Wiki Repositories Verified: succeeded 6789 / total 6789 (100%)
Sync Settings: Full
Database replication lag: 0 seconds
Last event ID seen from primary: 12345 (about 2 minutes ago)
Last event ID processed: 12345 (about 2 minutes ago)
Last status report was: 1 minute agoEach item can have up to three statuses. For example, for Project Repositories, you see the following lines:
Project Repositories: succeeded 12345 / total 12345 (100%)
Project Repositories Verified: succeeded 12345 / total 12345 (100%)
Repositories Checked: failed 5 / succeeded 0 / total 5 (0%)The 3 status items are defined as follows:
- The
Project Repositoriesoutput shows how many project repositories are synced from the primary to the secondary. - The
Project Verified Repositoriesoutput shows how many project repositories on this secondary have a matching repository checksum with the Primary. - The
Repositories Checkedoutput shows how many project repositories have passed a local Git repository check (git fsck) on the secondary.
To find more details about failed items, check
the gitlab-rails/geo.log file
If you notice replication or verification failures, you can try to resolve them.
If there are Repository check failures, you can try to resolve them.
Fixing errors found when running the Geo check Rake task
When running this Rake task, you may see error messages if the nodes are not properly configured:
sudo gitlab-rake gitlab:geo:check-
Rails did not provide a password when connecting to the database.
Checking Geo ... GitLab Geo is available ... Exception: fe_sendauth: no password supplied GitLab Geo is enabled ... Exception: fe_sendauth: no password supplied ... Checking Geo ... FinishedEnsure you have the
gitlab_rails['db_password']set to the plain-text password used when creating the hash forpostgresql['sql_user_password']. -
Rails is unable to connect to the database.
Checking Geo ... GitLab Geo is available ... Exception: FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL on FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL off GitLab Geo is enabled ... Exception: FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL on FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL off ... Checking Geo ... FinishedEnsure you have the IP address of the rails node included in
postgresql['md5_auth_cidr_addresses']. Also, ensure you have included the subnet mask on the IP address:postgresql['md5_auth_cidr_addresses'] = ['1.1.1.1/32']. -
Rails has supplied the incorrect password.
Checking Geo ... GitLab Geo is available ... Exception: FATAL: password authentication failed for user "gitlab" FATAL: password authentication failed for user "gitlab" GitLab Geo is enabled ... Exception: FATAL: password authentication failed for user "gitlab" FATAL: password authentication failed for user "gitlab" ... Checking Geo ... FinishedVerify the correct password is set for
gitlab_rails['db_password']that was used when creating the hash inpostgresql['sql_user_password']by runninggitlab-ctl pg-password-md5 gitlaband entering the password. -
Check returns
not a secondary node.Checking Geo ... GitLab Geo is available ... yes GitLab Geo is enabled ... yes GitLab Geo tracking database is correctly configured ... not a secondary node Database replication enabled? ... not a secondary node ... Checking Geo ... FinishedEnsure you have added the secondary site in the Admin Area under Geo > Sites on the web interface for the primary site. Also ensure you entered the
gitlab_rails['geo_node_name']when adding the secondary site in the Admin Area of the primary site. In GitLab 12.3 and earlier, edit the secondary site in the Admin Area of the primary site and ensure that there is a trailing/in theNamefield. -
Check returns
Exception: PG::UndefinedTable: ERROR: relation "geo_nodes" does not exist.Checking Geo ... GitLab Geo is available ... no Try fixing it: Add a new license that includes the GitLab Geo feature For more information see: https://about.gitlab.com/features/gitlab-geo/ GitLab Geo is enabled ... Exception: PG::UndefinedTable: ERROR: relation "geo_nodes" does not exist LINE 8: WHERE a.attrelid = '"geo_nodes"'::regclass ^ : SELECT a.attname, format_type(a.atttypid, a.atttypmod), pg_get_expr(d.adbin, d.adrelid), a.attnotnull, a.atttypid, a.atttypmod, c.collname, col_description(a.attrelid, a.attnum) AS comment FROM pg_attribute a LEFT JOIN pg_attrdef d ON a.attrelid = d.adrelid AND a.attnum = d.adnum LEFT JOIN pg_type t ON a.atttypid = t.oid LEFT JOIN pg_collation c ON a.attcollation = c.oid AND a.attcollation <> t.typcollation WHERE a.attrelid = '"geo_nodes"'::regclass AND a.attnum > 0 AND NOT a.attisdropped ORDER BY a.attnum ... Checking Geo ... FinishedWhen performing a PostgreSQL major version (9 > 10), update this is expected. Follow the initiate-the-replication-process.
-
Rails does not appear to have the configuration necessary to connect to the Geo tracking database.
Checking Geo ... GitLab Geo is available ... yes GitLab Geo is enabled ... yes GitLab Geo tracking database is correctly configured ... no Try fixing it: Rails does not appear to have the configuration necessary to connect to the Geo tracking database. If the tracking database is running on a node other than this one, then you may need to add configuration. ... Checking Geo ... Finished- If you are running the secondary site on a single node for all services, then follow Geo database replication - Configure the secondary server.
- If you are running the secondary site's tracking database on its own node, then follow Geo for multiple servers - Configure the Geo tracking database on the Geo secondary site
- If you are running the secondary site's tracking database in a Patroni cluster, then follow Geo database replication - Configure the tracking database on the secondary sites
- If you are running the secondary site's tracking database in an external database, then follow Geo with external PostgreSQL instances
- If the Geo check task was run on a node which is not running a service which runs the GitLab Rails app (Puma, Sidekiq, or Geo Log Cursor), then this error can be ignored. The node does not need Rails to be configured.
Message: Machine clock is synchronized ... Exception
The Rake task attempts to verify that the server clock is synchronized with NTP. Synchronized clocks are required for Geo to function correctly. As an example, for security, when the server time on the primary site and secondary site differ by about a minute or more, requests between Geo sites fail. If this check task fails to complete due to a reason other than mismatching times, it does not necessarily mean that Geo will not work.
The Ruby gem which performs the check is hard coded with pool.ntp.org as its reference time source.
-
Exception message
Machine clock is synchronized ... Exception: Timeout::ErrorThis issue occurs when your server cannot access the host
pool.ntp.org. -
Exception message
Machine clock is synchronized ... Exception: No route to host - recvfrom(2)This issue occurs when the hostname
pool.ntp.orgresolves to a server which does not provide a time service.
In this case, in GitLab 15.7 and newer, specify a custom NTP server using environment variables.
In GitLab 15.6 and older, use one of the following workarounds:
- Add entries in
/etc/hostsforpool.ntp.orgto direct the request to valid local time servers. This fixes the long timeout and the timeout error. - Direct the check to any valid IP address. This resolves the timeout issue, but the check fails
with the
No route to hosterror, as noted above.
Cloud native GitLab deployments generate an error because containers in Kubernetes do not have access to the host clock:
Machine clock is synchronized ... Exception: getaddrinfo: Servname not supported for ai_socktype
Message: ActiveRecord::StatementInvalid: PG::ReadOnlySqlTransaction: ERROR: cannot execute INSERT in a read-only transaction
When this error is encountered on a secondary site, it likely affects all usages of GitLab Rails such as gitlab-rails or gitlab-rake commands, as well the Puma, Sidekiq, and Geo Log Cursor services.
ActiveRecord::StatementInvalid: PG::ReadOnlySqlTransaction: ERROR: cannot execute INSERT in a read-only transaction
/opt/gitlab/embedded/service/gitlab-rails/app/models/application_record.rb:86:in `block in safe_find_or_create_by'
/opt/gitlab/embedded/service/gitlab-rails/app/models/concerns/cross_database_modification.rb:92:in `block in transaction'
/opt/gitlab/embedded/service/gitlab-rails/lib/gitlab/database.rb:332:in `block in transaction'
/opt/gitlab/embedded/service/gitlab-rails/lib/gitlab/database.rb:331:in `transaction'
/opt/gitlab/embedded/service/gitlab-rails/app/models/concerns/cross_database_modification.rb:83:in `transaction'
/opt/gitlab/embedded/service/gitlab-rails/app/models/application_record.rb:86:in `safe_find_or_create_by'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:21:in `by_name'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:17:in `block in populate!'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:17:in `map'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:17:in `populate!'
/opt/gitlab/embedded/service/gitlab-rails/config/initializers/fill_shards.rb:9:in `<top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/config/environment.rb:7:in `<top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'The PostgreSQL read-replica database would be producing these errors:
2023-01-17_17:44:54.64268 ERROR: cannot execute INSERT in a read-only transaction
2023-01-17_17:44:54.64271 STATEMENT: /*application:web,db_config_name:main*/ INSERT INTO "shards" ("name") VALUES ('storage1') RETURNING "id"This situation can occur during initial configuration when a secondary site is not yet aware that it is a secondary site.
To resolve the error, follow Step 3. Add the secondary site.
Check if PostgreSQL replication is working
To check if PostgreSQL replication is working, check if:
Are sites pointing to the correct database node?
You should make sure your primary Geo site points to the database node that has write permissions.
Any secondary sites should point only to read-only database nodes.
Can Geo detect the current site correctly?
Geo finds the current Puma or Sidekiq node's Geo site name in
/etc/gitlab/gitlab.rb with the following logic:
- Get the "Geo node name" (there is
an issue to rename the settings to "Geo site name"):
- Linux package: get the
gitlab_rails['geo_node_name']setting. - GitLab Helm charts: get the
global.geo.nodeNamesetting (see Charts with GitLab Geo).
- Linux package: get the
- If that is not defined, then get the
external_urlsetting.
This name is used to look up the Geo site with the same Name in the Geo Sites dashboard.
To check if the current machine has a site name that matches a site in the database, run the check task:
sudo gitlab-rake gitlab:geo:checkIt displays the current machine's site name and whether the matching database record is a primary or secondary site.
This machine's Geo node name matches a database record ... yes, found a secondary node named "Shanghai"This machine's Geo node name matches a database record ... no
Try fixing it:
You could add or update a Geo node database record, setting the name to "https://example.com/".
Or you could set this machine's Geo node name to match the name of an existing database record: "London", "Shanghai"
For more information see:
doc/administration/geo/replication/troubleshooting.md#can-geo-detect-the-current-node-correctlyFor more information about recommended site names in the description of the Name field, see Geo Admin Area Common Settings.
Check OS locale data compatibility
If different operating systems or different operating system versions are deployed across Geo sites, you must perform a locale data compatibility check before setting up Geo.
Geo uses PostgreSQL and Streaming Replication to replicate data across Geo sites. PostgreSQL uses locale data provided by the operating system's C library for sorting text. If the locale data in the C library is incompatible across Geo sites, it causes erroneous query results that lead to incorrect behavior on secondary sites.
For example, Ubuntu 18.04 (and earlier) and RHEL/Centos7 (and earlier) are incompatible with their later releases. See the PostgreSQL wiki for more details.
On all hosts running PostgreSQL, across all Geo sites, run the following shell command:
( echo "1-1"; echo "11" ) | LC_COLLATE=en_US.UTF-8 sortThe output looks like either:
1-1
11or the reverse order:
11
1-1If the output is identical on all hosts, then they running compatible versions of locale data and you may proceed with Geo configuration.
If the output differs on any hosts, PostgreSQL replication will not work properly: indexes will become corrupted on the database replicas. You must select operating system versions that are compatible.
A full index rebuild is required if the on-disk data is transferred 'at rest' to an operating system with an incompatible locale, or through replication.
This check is also required when using a mixture of GitLab deployments. The locale might be different between an Linux package install, a GitLab Docker container, a Helm chart deployment, or external database services.
Fixing PostgreSQL database replication errors
The following sections outline troubleshooting steps for fixing replication error messages (indicated by Database replication working? ... no in the
geo:check output.
The instructions present here mostly assume a single-node Geo Linux package deployment, and might need to be adapted to different environments.
Removing an inactive replication slot
Replication slots are marked as 'inactive' when the replication client (a secondary site) connected to the slot disconnects. Inactive replication slots cause WAL files to be retained, because they are sent to the client when it reconnects and the slot becomes active once more. If the secondary site is not able to reconnect, use the following steps to remove its corresponding inactive replication slot:
-
Start a PostgreSQL console session on the Geo primary site's database node:
sudo gitlab-psql -d gitlabhq_productionNOTE: Using
gitlab-rails dbconsoledoes not work, because managing replication slots requires superuser permissions. -
View the replication slots and remove them if they are inactive:
SELECT * FROM pg_replication_slots;Slots where
activeisfare inactive.-
When this slot should be active, because you have a secondary site configured using that slot, look for the PostgreSQL logs for the secondary site, to view why the replication is not running.
-
If you are no longer using the slot (for example, you no longer have Geo enabled), or the secondary site is no longer able to reconnect, you should remove it using the PostgreSQL console session:
SELECT pg_drop_replication_slot('<name_of_inactive_slot>');
-
-
Follow either the steps to remove that Geo site if it's no longer required, or re-initiate the replication process, which recreates the replication slot correctly.
Message: WARNING: oldest xmin is far in the past and pg_wal size growing
If a replication slot is inactive,
the pg_wal logs corresponding to the slot are reserved forever
(or until the slot is active again). This causes continuous disk usage growth
and the following messages appear repeatedly in the
PostgreSQL logs:
WARNING: oldest xmin is far in the past
HINT: Close open transactions soon to avoid wraparound problems.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.To fix this, you should remove the inactive replication slot and re-initiate the replication.
Message: ERROR: replication slots can only be used if max_replication_slots > 0?
This means that the max_replication_slots PostgreSQL variable needs to
be set on the primary database. This setting defaults to 1. You may need to
increase this value if you have more secondary sites.
Be sure to restart PostgreSQL for this to take effect. See the PostgreSQL replication setup guide for more details.
Message: FATAL: could not start WAL streaming: ERROR: replication slot "geo_secondary_my_domain_com" does not exist?
This occurs when PostgreSQL does not have a replication slot for the secondary site by that name.
You may want to rerun the replication process on the secondary site .
Message: "Command exceeded allowed execution time" when setting up replication?
This may happen while initiating the replication process on the secondary site, and indicates your initial dataset is too large to be replicated in the default timeout (30 minutes).
Re-run gitlab-ctl replicate-geo-database, but include a larger value for
--backup-timeout:
sudo gitlab-ctl \
replicate-geo-database \
--host=<primary_node_hostname> \
--slot-name=<secondary_slot_name> \
--backup-timeout=21600This gives the initial replication up to six hours to complete, rather than the default 30 minutes. Adjust as required for your installation.
Message: "PANIC: could not write to file pg_xlog/xlogtemp.123: No space left on device"
Determine if you have any unused replication slots in the primary database. This can cause large amounts of
log data to build up in pg_xlog.
Removing the inactive slots can reduce the amount of space used in the pg_xlog.
Message: "ERROR: canceling statement due to conflict with recovery"
This error message occurs infrequently under typical usage, and the system is resilient enough to recover.
However, under certain conditions, some database queries on secondaries may run excessively long, which increases the frequency of this error message. This can lead to a situation where some queries never complete due to being canceled on every replication.
These long-running queries are
planned to be removed in the future,
but as a workaround, we recommend enabling
hot_standby_feedback.
This increases the likelihood of bloat on the primary site as it prevents
VACUUM from removing recently-dead rows. However, it has been used
successfully in production on GitLab.com.
To enable hot_standby_feedback, add the following to /etc/gitlab/gitlab.rb
on the secondary site:
postgresql['hot_standby_feedback'] = 'on'Then reconfigure GitLab:
sudo gitlab-ctl reconfigureTo help us resolve this problem, consider commenting on the issue.
Message: FATAL: could not connect to the primary server: server certificate for "PostgreSQL" does not match host name
This happens because the PostgreSQL certificate that the Linux package automatically creates contains
the Common Name PostgreSQL, but the replication is connecting to a different host and GitLab attempts to use
the verify-full SSL mode by default.
To fix this issue, you can either:
- Use the
--sslmode=verify-caargument with thereplicate-geo-databasecommand. - For an already replicated database, change
sslmode=verify-fulltosslmode=verify-cain/var/opt/gitlab/postgresql/data/gitlab-geo.confand rungitlab-ctl restart postgresql. - Configure SSL for PostgreSQL with a custom certificate (including the host name that's used to connect to the database in the CN or SAN) instead of using the automatically generated certificate.
Message: LOG: invalid CIDR mask in address
This happens on wrongly-formatted addresses in postgresql['md5_auth_cidr_addresses'].
2020-03-20_23:59:57.60499 LOG: invalid CIDR mask in address "***"
2020-03-20_23:59:57.60501 CONTEXT: line 74 of configuration file "/var/opt/gitlab/postgresql/data/pg_hba.conf"To fix this, update the IP addresses in /etc/gitlab/gitlab.rb under postgresql['md5_auth_cidr_addresses']
to respect the CIDR format (for example, 10.0.0.1/32).
Message: LOG: invalid IP mask "md5": Name or service not known
This happens when you have added IP addresses without a subnet mask in postgresql['md5_auth_cidr_addresses'].
2020-03-21_00:23:01.97353 LOG: invalid IP mask "md5": Name or service not known
2020-03-21_00:23:01.97354 CONTEXT: line 75 of configuration file "/var/opt/gitlab/postgresql/data/pg_hba.conf"To fix this, add the subnet mask in /etc/gitlab/gitlab.rb under postgresql['md5_auth_cidr_addresses']
to respect the CIDR format (for example, 10.0.0.1/32).
Message: Found data in the gitlabhq_production database! when running gitlab-ctl replicate-geo-database
This happens if data is detected in the projects table. When one or more projects are detected, the operation
is aborted to prevent accidental data loss. To bypass this message, pass the --force option to the command.
In GitLab 13.4, a seed project is added when GitLab is first installed. This makes it necessary to pass --force even
on a new Geo secondary site. There is an issue to account for seed projects
when checking the database.
Message: FATAL: could not map anonymous shared memory: Cannot allocate memory
If you see this message, it means that the secondary site's PostgreSQL tries to request memory that is higher than the available memory. There is an issue that tracks this problem.
Example error message in Patroni logs (located at /var/log/gitlab/patroni/current for Linux package installations):
2023-11-21_23:55:18.63727 FATAL: could not map anonymous shared memory: Cannot allocate memory
2023-11-21_23:55:18.63729 HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded available memory, swap space, or huge pages. To reduce the request size (currently 17035526144 bytes), reduce PostgreSQL's shared memory usage, perhaps by reducing shared_buffers or max_connections.The workaround is to increase the memory available to the secondary site's PostgreSQL nodes to match the memory requirements of the primary site's PostgreSQL nodes.
Synchronization errors
Reverify all uploads (or any SSF data type which is verified)
- SSH into a GitLab Rails node in the primary Geo site.
- Open Rails console.
- Mark all uploads as "pending verification":
WARNING: Commands that change data can cause damage if not run correctly or under the right conditions. Always run commands in a test environment first and have a backup instance ready to restore.
Upload.verification_state_table_class.each_batch do |relation|
relation.update_all(verification_state: 0)
end- This causes the primary to start checksumming all Uploads.
- When a primary successfully checksums a record, then all secondaries recalculate the checksum as well, and they compare the values.
You can perform a similar operation with other the Models handled by the Geo Self-Service Framework which have implemented verification:
LfsObjectMergeRequestDiffPackages::PackageFileTerraform::StateVersionSnippetRepositoryCi::PipelineArtifactPagesDeploymentUploadCi::JobArtifactCi::SecureFile
NOTE:
GroupWikiRepository is not in the previous list since verification is not implemented.
There is an issue to implement this functionality in the Admin Area UI.
Message: Synchronization failed - Error syncing repository
WARNING: If large repositories are affected by this problem, their resync may take a long time and cause significant load on your Geo sites, storage and network systems.
The following error message indicates a consistency check error when syncing the repository:
Synchronization failed - Error syncing repository [..] fatal: fsck error in packed objectSeveral issues can trigger this error. For example, problems with email addresses:
Error syncing repository: 13:fetch remote: "error: object <SHA>: badEmail: invalid author/committer line - bad email
fatal: fsck error in packed object
fatal: fetch-pack: invalid index-pack outputAnother issue that can trigger this error is object <SHA>: hasDotgit: contains '.git'. Check the specific errors because you might have more than one problem across all
your repositories.
A second synchronization error can also be caused by repository check issues:
Error syncing repository: 13:Received RST_STREAM with error code 2.These errors can be observed by immediately syncing all failed repositories.
Removing the malformed objects causing consistency errors involves rewriting the repository history, which is usually not an option.
To ignore these consistency checks, reconfigure Gitaly on the secondary Geo sites to ignore these git fsck issues.
The following configuration example:
- Uses the new configuration structure required from GitLab 16.0.
- Ignores five common check failures.
The Gitaly documentation has more details about other Git check failures and older versions of GitLab.
gitaly['configuration'] = {
git: {
config: [
{ key: "fsck.duplicateEntries", value: "ignore" },
{ key: "fsck.badFilemode", value: "ignore" },
{ key: "fsck.missingEmail", value: "ignore" },
{ key: "fsck.badEmail", value: "ignore" },
{ key: "fsck.hasDotgit", value: "ignore" },
{ key: "fetch.fsck.duplicateEntries", value: "ignore" },
{ key: "fetch.fsck.badFilemode", value: "ignore" },
{ key: "fetch.fsck.missingEmail", value: "ignore" },
{ key: "fetch.fsck.badEmail", value: "ignore" },
{ key: "fetch.fsck.hasDotgit", value: "ignore" },
{ key: "receive.fsck.duplicateEntries", value: "ignore" },
{ key: "receive.fsck.badFilemode", value: "ignore" },
{ key: "receive.fsck.missingEmail", value: "ignore" },
{ key: "receive.fsck.badEmail", value: "ignore" },
{ key: "receive.fsck.hasDotgit", value: "ignore" },
],
},
}GitLab 16.1 and later include an enhancement that might resolve some of these issues.
Gitaly issue 5625 proposes to ensure that Geo replicates repositories even if the source repository contains problematic commits.
Related error does not appear to be a git repository
You can also get the error message Synchronization failed - Error syncing repository along with the following log messages.
This error indicates that the expected Geo remote is not present in the .git/config file
of a repository on the secondary Geo site's file system:
{
"created": "@1603481145.084348757",
"description": "Error received from peer unix:/var/opt/gitlab/gitaly/gitaly.socket",
…
"grpc_message": "exit status 128",
"grpc_status": 13
}
{ …
"grpc.request.fullMethod": "/gitaly.RemoteService/FindRemoteRootRef",
"grpc.request.glProjectPath": "<namespace>/<project>",
…
"level": "error",
"msg": "fatal: 'geo' does not appear to be a git repository
fatal: Could not read from remote repository. …",
}To solve this:
-
Sign in on the web interface for the secondary Geo site.
-
Back up the
.gitfolder. -
Optional. Spot-check a few of those IDs whether they indeed correspond to a project with known Geo replication failures. Use
fatal: 'geo'as thegrepterm and the following API call:curl --request GET --header "PRIVATE-TOKEN: <your_access_token>" "https://gitlab.example.com/api/v4/projects/<first_failed_geo_sync_ID>" -
Enter the Rails console and run:
failed_geo_syncs = Geo::ProjectRegistry.failed.pluck(:id) failed_geo_syncs.each do |fgs| puts Geo::ProjectRegistry.failed.find(fgs).project_id end -
Run the following commands to reset each project's Geo-related attributes and execute a new sync:
failed_geo_syncs.each do |fgs| registry = Geo::ProjectRegistry.failed.find(fgs) registry.update(resync_repository: true, force_to_redownload_repository: false, repository_retry_count: 0) Geo::RepositorySyncService.new(registry.project).execute end
Failures during backfill
During a backfill, failures are scheduled to be retried at the end of the backfill queue, therefore these failures only clear up after the backfill completes.
Sync failure message: "Verification failed with: Error during verification: File is not checksummable"
Missing files on the Geo primary site
In GitLab 14.5 and earlier, certain data types which were missing on the Geo primary site were marked as "synced" on Geo secondary sites. This was because from the perspective of Geo secondary sites, the state matched the primary site and nothing more could be done on secondary sites.
Secondaries would regularly try to sync these files again by using the "verification" feature:
- Verification fails since the file doesn't exist.
- The file is marked "sync failed".
- Sync is retried.
- The file is marked "sync succeeded".
- The file is marked "needs verification".
- Repeat until the file is available again on the primary site.
This can be confusing to troubleshoot, since the registry entries are moved through a logical loop by various background jobs. Also, last_sync_failure and verification_failure are empty after "sync succeeded" but before verification is retried.
If you see sync failures repeatedly and alternately increase, while successes decrease and vice versa, this is likely to be caused by missing files on the primary site. You can confirm this by searching geo.log on secondary sites for File is not checksummable affecting the same files over and over.
After confirming this is the problem, the files on the primary site need to be fixed. Some possible causes:
- An NFS share became unmounted.
- A disk died or became corrupted.
- Someone unintentionally deleted a file or directory.
- Bugs in GitLab application:
- A file was moved when it shouldn't have been moved.
- A file wasn't moved when it should have been moved.
- A wrong path was generated in the code.
- A non-atomic backup was restored.
- Services or servers or network infrastructure was interrupted/restarted during use.
The appropriate action sometimes depends on the cause. For example, you can remount an NFS share. Often, a root cause may not be apparent or not useful to discover. If you have regular backups, it may be expedient to look through them and pull files from there.
In some cases, a file may be determined to be of low value, and so it may be worth deleting the record.
Geo itself is an excellent mitigation for files missing on the primary. If a file disappears on the primary but it was already synced to the secondary, you can grab the secondary's file. In cases like this, the File is not checksummable error message does not occur on Geo secondary sites, and only the primary logs this error message.
This problem is more likely to show up in Geo secondary sites which were set up long after the original GitLab site. In this case, Geo is only surfacing an existing problem.
This behavior affects only the following data types through GitLab 14.6:
| Data type | From version |
|---|---|
| Package registry | 13.10 |
| CI Pipeline Artifacts | 13.11 |
| Terraform State Versions | 13.12 |
| Infrastructure Registry (renamed to Terraform Module Registry in GitLab 15.11) | 14.0 |
| External MR diffs | 14.6 |
| LFS Objects | 14.6 |
| Pages Deployments | 14.6 |
| Uploads | 14.6 |
| CI Job Artifacts | 14.6 |
Since GitLab 14.7, files that are missing on the primary site are now treated as sync failures
to make Geo visibly surface data loss risks. The sync/verification loop is
therefore short-circuited. last_sync_failure is now set to The file is missing on the Geo primary site.
Failed syncs with GitLab-managed object storage replication
There is an issue in GitLab 14.2 through 14.7 that affects Geo when the GitLab-managed object storage replication is used, causing blob object types to fail synchronization.
Since GitLab 14.2, verification failures result in synchronization failures and cause a re-synchronization of these objects.
As verification is not implemented for files stored in object storage (see issue 13845 for more details), this results in a loop that consistently fails for all objects stored in object storage.
You can work around this by marking the objects as synced and succeeded verification, however be aware that can also mark objects that may be missing from the primary.
To do that, enter the Rails console and run:
Gitlab::Geo.verification_enabled_replicator_classes.each do |klass|
updated = klass.registry_class.failed.where(last_sync_failure: "Verification failed with: Error during verification: File is not checksummable").update_all(verification_checksum: '0000000000000000000000000000000000000000', verification_state: 2, verification_failure: nil, verification_retry_at: nil, state: 2, last_sync_failure: nil, retry_at: nil, verification_retry_count: 0, retry_count: 0)
pp "Updated #{updated} #{klass.replicable_name_plural}"
endMessage: curl 18 transfer closed with outstanding read data remaining & fetch-pack: unexpected disconnect while reading sideband packet
Unstable networking conditions can cause Gitaly to fail when trying to fetch large repository data from the primary site. This is more likely to happen if a repository has to be replicated from scratch between sites.
Geo retries several times, but if the transmission is consistently interrupted
by network hiccups, an alternative method such as rsync can be used to circumvent git and
create the initial copy of any repository that fails to be replicated by Geo.
We recommend transferring each failing repository individually and checking for consistency
after each transfer. Follow the single target rsync instructions
to transfer each affected repository from the primary to the secondary site.
Project or project wiki repositories
Find repository verification failures
Start a Rails console session on the secondary Geo site to gather more information.
WARNING: Commands that change data can cause damage if not run correctly or under the right conditions. Always run commands in a test environment first and have a backup instance ready to restore.
Get the number of verification failed repositories
Geo::ProjectRegistry.verification_failed('repository').countFind the verification failed repositories
Geo::ProjectRegistry.verification_failed('repository')Find repositories that failed to sync
Geo::ProjectRegistry.sync_failed('repository')Resync project and project wiki repositories
Start a Rails console session on the secondary Geo site to perform the following changes.
WARNING: Commands that change data can cause damage if not run correctly or under the right conditions. Always run commands in a test environment first and have a backup instance ready to restore.
Queue up all repositories for resync
When you run this, the sync is handled in the background by Sidekiq.
Geo::ProjectRegistry.update_all(resync_repository: true, resync_wiki: true)Sync individual repository now
project = Project.find_by_full_path('<group/project>')
Geo::RepositorySyncService.new(project).executeSync all failed repositories now
The following script:
- Loops over all currently failed repositories.
- Displays the project details and the reasons for the last failure.
- Attempts to resync the repository.
- Reports back if a failure occurs, and why.
- Might take some time to complete. Each repository check must complete
before reporting back the result. If your session times out, take measures
to allow the process to continue running such as starting a
screensession, or running it using Rails runner andnohup.
Geo::ProjectRegistry.sync_failed('repository').find_each do |p|
begin
project = p.project
puts "#{project.full_path} | id: #{p.project_id} | last error: '#{p.last_repository_sync_failure}'"
Geo::RepositorySyncService.new(project).execute
rescue => e
puts "ID: #{p.project_id} failed: '#{e}'", e.backtrace.join("\n")
end
end ; nilFind repository check failures in a Geo secondary site
When enabled for all projects, Repository checks are also performed on Geo secondary sites. The metadata is stored in the Geo tracking database.
Repository check failures on a Geo secondary site do not necessarily imply a replication problem. Here is a general approach to resolve these failures.
- Find affected repositories as mentioned below, as well as their logged errors.
- Try to diagnose specific
git fsckerrors. The range of possible errors is wide, try putting them into search engines. - Test typical functions of the affected repositories. Pull from the secondary, view the files.
- Check if the primary site's copy of the repository has an identical
git fsckerror. If you are planning a failover, then consider prioritizing that the secondary site has the same information that the primary site has. Ensure you have a backup of the primary, and follow planned failover guidelines. - Push to the primary and check if the change gets replicated to the secondary site.
- If replication is not automatically working, try to manually sync the repository.
Start a Rails console session to enact the following, basic troubleshooting steps.
WARNING: Commands that change data can cause damage if not run correctly or under the right conditions. Always run commands in a test environment first and have a backup instance ready to restore.
Get the number of repositories that failed the repository check
Geo::ProjectRegistry.where(last_repository_check_failed: true).countFind the repositories that failed the repository check
Geo::ProjectRegistry.where(last_repository_check_failed: true)Recheck repositories that failed the repository check
When you run this, fsck is executed against each failed repository.
The fsck Rake command can be used on the secondary site to understand why the repository check might be failing.
Geo::ProjectRegistry.where(last_repository_check_failed: true).each do |pr|
RepositoryCheck::SingleRepositoryWorker.new.perform(pr.project_id)
endFixing non-PostgreSQL replication failures
If you notice replication failures in Admin > Geo > Sites or the Sync status Rake task, you can try to resolve the failures with the following general steps:
- Geo automatically retries failures. If the failures are new and few in number, or if you suspect the root cause is already resolved, then you can wait to see if the failures go away.
- If failures were present for a long time, then many retries have already occurred, and the interval between automatic retries has increased to up to 4 hours depending on the type of failure. If you suspect the root cause is already resolved, you can manually retry replication or verification.
- If the failures persist, use the following sections to try to resolve them.
Manually retry replication or verification
A Geo data type is a specific class of data that is required by one or more GitLab features to store relevant information and is replicated by Geo to secondary sites.
The following Geo data types exist:
-
Blob types:
Ci::JobArtifactCi::PipelineArtifactCi::SecureFileLfsObjectMergeRequestDiffPackages::PackageFilePagesDeploymentTerraform::StateVersionUploadDependencyProxy::ManifestDependencyProxy::Blob
-
Repository types:
ContainerRepositoryRegistryDesignManagement::RepositoryProjectRepositoryProjectWikiRepositorySnippetRepositoryGroupWikiRepository
The main kinds of classes are Registry, Model, and Replicator. If you have an instance of one of these classes, you can get the others. The Registry and Model mostly manage PostgreSQL DB state. The Replicator knows how to replicate/verify (or it can call a service to do it):
model_record = Packages::PackageFile.last
model_record.replicator.registry.replicator.model_record # just showing that these methods existWith all this information, you can:
Resync and reverify individual components
You can force a resync and reverify individual items for all component types managed by the self-service framework using the UI. On the secondary site, visit Admin > Geo > Replication.
However, if this doesn't work, you can perform the same action using the Rails console. The following sections describe how to use internal application commands in the Rails console to cause replication or verification for individual records synchronously or asynchronously.
WARNING: Commands that change data can cause damage if not run correctly or under the right conditions. Always run commands in a test environment first and have a backup instance ready to restore.
Start a Rails console session to enact the following, basic troubleshooting steps:
-
For Blob types (using the
Packages::PackageFilecomponent as an example)-
Find registry records that failed to sync:
Geo::PackageFileRegistry.failed -
Find registry records that are missing on the primary site:
Geo::PackageFileRegistry.where(last_sync_failure: 'The file is missing on the Geo primary site') -
Resync a package file, synchronously, given an ID:
model_record = Packages::PackageFile.find(id) model_record.replicator.send(:download) -
Resync a package file, synchronously, given a registry ID:
registry = Geo::PackageFileRegistry.find(registry_id) registry.replicator.send(:download) -
Resync a package file, asynchronously, given a registry ID. Since GitLab 16.2, a component can be asynchronously replicated as follows:
registry = Geo::PackageFileRegistry.find(registry_id) registry.replicator.enqueue_sync -
Reverify a package file, asynchronously, given a registry ID. Since GitLab 16.2, a component can be asynchronously reverified as follows:
registry = Geo::PackageFileRegistry.find(registry_id) registry.replicator.verify_async
-
-
For Repository types (using the
SnippetRepositorycomponent as an example)-
Resync a snippet repository, synchronously, given an ID:
model_record = Geo::SnippetRepositoryRegistry.find(id) model_record.replicator.sync_repository -
Resync a snippet repository, synchronously, given a registry ID
registry = Geo::SnippetRepositoryRegistry.find(registry_id) registry.replicator.sync_repository -
Resync a snippet repository, asynchronously, given a registry ID. Since GitLab 16.2, a component can be asynchronously replicated as follows:
registry = Geo::SnippetRepositoryRegistry.find(registry_id) registry.replicator.enqueue_sync -
Reverify a snippet repository, asynchronously, given a registry ID. Since GitLab 16.2, a component can be asynchronously reverified as follows:
registry = Geo::SnippetRepositoryRegistry.find(registry_id) registry.replicator.verify_async
-
Resync and reverify multiple components
NOTE: There is an issue to implement this functionality in the Admin Area UI.
WARNING: Commands that change data can cause damage if not run correctly or under the right conditions. Always run commands in a test environment first and have a backup instance ready to restore.
The following sections describe how to use internal application commands in the Rails console to cause bulk replication or verification.
Reverify all components (or any SSF data type which supports verification)
For GitLab 16.4 and earlier:
-
SSH into a GitLab Rails node in the primary Geo site.
-
Open the Rails console.
-
Mark all uploads as
pending verification:Upload.verification_state_table_class.each_batch do |relation| relation.update_all(verification_state: 0) end -
This causes the primary to start checksumming all Uploads.
-
When a primary successfully checksums a record, then all secondaries recalculate the checksum as well, and they compare the values.
For other SSF data types replace Upload in the command above with the desired model class.
Verify blob files on the secondary manually
This iterates over all package files on the secondary, looking at the
verification_checksum stored in the database (which came from the primary)
and then calculate this value on the secondary to check if they match. This
does not change anything in the UI.
For GitLab 14.4 and later:
# Run on secondary
status = {}
Packages::PackageFile.find_each do |package_file|
primary_checksum = package_file.verification_checksum
secondary_checksum = Packages::PackageFile.sha256_hexdigest(package_file.file.path)
verification_status = (primary_checksum == secondary_checksum)
status[verification_status.to_s] ||= []
status[verification_status.to_s] << package_file.id
end
# Count how many of each value we get
status.keys.each {|key| puts "#{key} count: #{status[key].count}"}
# See the output in its entirety
statusFor GitLab 14.3 and earlier:
# Run on secondary
status = {}
Packages::PackageFile.find_each do |package_file|
primary_checksum = package_file.verification_checksum
secondary_checksum = Packages::PackageFile.hexdigest(package_file.file.path)
verification_status = (primary_checksum == secondary_checksum)
status[verification_status.to_s] ||= []
status[verification_status.to_s] << package_file.id
end
# Count how many of each value we get
status.keys.each {|key| puts "#{key} count: #{status[key].count}"}
# See the output in its entirety
statusFailed verification of Uploads on the primary Geo site
If verification of some uploads is failing on the primary Geo site with verification_checksum = nil and with the verification_failure = Error during verification: undefined method `underscore' for NilClass:Class, this can be due to orphaned Uploads. The parent record owning the Upload (the upload's model) has somehow been deleted, but the Upload record still exists. These verification failures are false.
You can find these errors in the geo.log file on the primary Geo site.
To confirm that model records are missing, you can run a Rake task on the primary Geo site:
sudo gitlab-rake gitlab:uploads:checkYou can delete these Upload records on the primary Geo site to get rid of these failures by running the following script from the Rails console:
# Look for uploads with the verification error
# or edit with your own affected IDs
uploads = Geo::UploadState.where(
verification_checksum: nil,
verification_state: 3,
verification_failure: "Error during verification: undefined method `underscore' for NilClass:Class"
).pluck(:upload_id)
uploads_deleted = 0
begin
uploads.each do |upload|
u = Upload.find upload
rescue => e
puts "checking upload #{u.id} failed with #{e.message}"
else
uploads_deleted=uploads_deleted + 1
p u ### allow verification before destroy
# p u.destroy! ### uncomment to actually destroy
end
end
p "#{uploads_deleted} remote objects were destroyed."HTTP response code errors
Secondary site returns 502 errors with Geo proxying
When Geo proxying for secondary sites is enabled, and the secondary site user interface returns 502 errors, it is possible that the response header proxied from the primary site is too large.
Check the NGINX logs for errors similar to this example:
2022/01/26 00:02:13 [error] 26641#0: *829148 upstream sent too big header while reading response header from upstream, client: 10.0.2.2, server: geo.staging.gitlab.com, request: "POST /users/sign_in HTTP/2.0", upstream: "http://unix:/var/opt/gitlab/gitlab-workhorse/sockets/socket:/users/sign_in", host: "geo.staging.gitlab.com", referrer: "https://geo.staging.gitlab.com/users/sign_in"To resolve this issue:
- Set
nginx['proxy_custom_buffer_size'] = '8k'in/etc/gitlab.rbon all web nodes on the secondary site. - Reconfigure the secondary using
sudo gitlab-ctl reconfigure.
If you still get this error, you can further increase the buffer size by repeating the steps above
and changing the 8k size, for example by doubling it to 16k.
Geo Admin Area shows 'Unknown' for health status and 'Request failed with status code 401'
If using a load balancer, ensure that the load balancer's URL is set as the external_url in the
/etc/gitlab/gitlab.rb of the nodes behind the load balancer.
Primary site returns 500 error when accessing /admin/geo/replication/projects
Navigating to Admin > Geo > Replication (or /admin/geo/replication/projects) on a primary Geo site, shows a 500 error, while that same link on the secondary works fine. The primary's production.log has a similar entry to the following:
Geo::TrackingBase::SecondaryNotConfigured: Geo secondary database is not configured
from ee/app/models/geo/tracking_base.rb:26:in `connection'
[..]
from ee/app/views/admin/geo/projects/_all.html.haml:1On a Geo primary site this error can be ignored.
This happens because GitLab is attempting to display registries from the Geo tracking database which doesn't exist on the primary site (only the original projects exist on the primary; no replicated projects are present, therefore no tracking database exists).
Secondary site returns 400 error "Request header or cookie too large"
This error can happen when the internal URL of the primary site is incorrect.
For example, when you use a unified URL and the primary site's internal URL is also equal to the external URL. This causes a loop when a secondary site proxies requests to the primary site's internal URL.
To fix this issue, set the primary site's internal URL to a URL that is:
- Unique to the primary site.
- Accessible from all secondary sites.
- Visit the primary site.
- Set up the internal URLs.
Secondary site returns Received HTTP code 403 from proxy after CONNECT
If you have installed GitLab using the Linux package (Omnibus) and have configured the no_proxy custom environment variable for Gitaly, you may experience this issue. Affected versions:
15.4.6-
15.5.0-15.5.6 -
15.6.0-15.6.3 -
15.7.0-15.7.1
This is due to a bug introduced in the included version of cURL shipped with the Linux package 15.4.6 and later. You should upgrade to a later version where this has been fixed.
The bug causes all wildcard domains (.example.com) to be ignored except for the last on in the no_proxy environment variable list. Therefore, if for any reason you cannot upgrade to a newer version, you can work around the issue by moving your wildcard domain to the end of the list:
-
Edit
/etc/gitlab/gitlab.rb:gitaly['env'] = { "no_proxy" => "sever.yourdomain.org, .yourdomain.com", } -
Reconfigure GitLab:
sudo gitlab-ctl reconfigure
You can have only one wildcard domain in the no_proxy list.
Geo Admin Area returns 404 error for a secondary site
Sometimes sudo gitlab-rake gitlab:geo:check indicates that Rails nodes of the secondary sites are
healthy, but a 404 Not Found error message for the secondary site is returned in the Geo Admin Area on the web interface for
the primary site.
To resolve this issue:
- Try restarting each Rails, Sidekiq and Gitaly nodes on your secondary site using
sudo gitlab-ctl restart. - Check
/var/log/gitlab/gitlab-rails/geo.logon Sidekiq nodes to see if the secondary site is using IPv6 to send its status to the primary site. If it is, add an entry to the primary site using IPv4 in the/etc/hostsfile. Alternatively, you should enable IPv6 on the primary site.
Fixing common errors
This section documents common error messages reported in the Admin Area on the web interface, and how to fix them.
Geo database configuration file is missing
GitLab cannot find or doesn't have permission to access the database_geo.yml configuration file.
In a Linux package installation, the file should be in /var/opt/gitlab/gitlab-rails/etc.
If it doesn't exist or inadvertent changes have been made to it, run sudo gitlab-ctl reconfigure to restore it to its correct state.
If this path is mounted on a remote volume, ensure your volume configuration has the correct permissions.
An existing tracking database cannot be reused
Geo cannot reuse an existing tracking database.
It is safest to use a fresh secondary, or reset the whole secondary by following Resetting Geo secondary site replication.
Geo site has a database that is writable which is an indication it is not configured for replication with the primary site
This error message refers to a problem with the database replica on a secondary site, which Geo expects to have access to. It usually means, either:
- An unsupported replication method was used (for example, logical replication).
- The instructions to set up a Geo database replication were not followed correctly.
- Your database connection details are incorrect, that is you have specified the wrong
user in your
/etc/gitlab/gitlab.rbfile.
Geo secondary sites require two separate PostgreSQL instances:
- A read-only replica of the primary site.
- A regular, writable instance that holds replication metadata. That is, the Geo tracking database.
This error message indicates that the replica database in the secondary site is misconfigured and replication has stopped.
To restore the database and resume replication, you can do one of the following:
If you set up a new secondary from scratch, you must also remove the old site from the Geo cluster.
Geo site does not appear to be replicating the database from the primary site
The most common problems that prevent the database from replicating correctly are:
- Secondary sites cannot reach the primary site. Check credentials and firewall rules.
- SSL certificate problems. Make sure you copied
/etc/gitlab/gitlab-secrets.jsonfrom the primary site. - Database storage disk is full.
- Database replication slot is misconfigured.
- Database is not using a replication slot or another alternative and cannot catch-up because WAL files were purged.
Make sure you follow the Geo database replication instructions for supported configuration.
Geo database version (...) does not match latest migration (...)
If you are using the Linux package installation, something might have failed during upgrade. You can:
- Run
sudo gitlab-ctl reconfigure. - Manually trigger the database migration by running:
sudo gitlab-rake db:migrate:geoas root on the secondary site.
GitLab indicates that more than 100% of repositories were synced
This can be caused by orphaned records in the project registry. They are being cleaned periodically using a registry worker, so give it some time to fix it itself.
Secondary site shows "Unhealthy" in UI after changing the value of external_url for the primary site
If you have updated the value of external_url in /etc/gitlab/gitlab.rb for the primary site or changed the protocol from http to https, you may see that secondary sites are shown as Unhealthy. You may also find the following error in geo.log:
"class": "Geo::NodeStatusRequestService",
...
"message": "Failed to Net::HTTP::Post to primary url: http://primary-site.gitlab.tld/api/v4/geo/status",
"error": "Failed to open TCP connection to <PRIMARY_IP_ADDRESS>:80 (Connection refused - connect(2) for \"<PRIMARY_ID_ADDRESS>\" port 80)"In this case, make sure to update the changed URL on all your sites:
- On the left sidebar, at the bottom, select Admin Area.
- Select Geo > Sites.
- Change the URL and save the change.
Message: ERROR: canceling statement due to conflict with recovery during backup
Running a backup on a Geo secondary is not supported.
When running a backup on a secondary you might encounter the following error message:
Dumping PostgreSQL database gitlabhq_production ...
pg_dump: error: Dumping the contents of table "notes" failed: PQgetResult() failed.
pg_dump: error: Error message from server: ERROR: canceling statement due to conflict with recovery
DETAIL: User query might have needed to see row versions that must be removed.
pg_dump: error: The command was: COPY public.notes (id, note, [...], last_edited_at) TO stdout;To prevent a database backup being made automatically during GitLab upgrades on your Geo secondaries, create the following empty file:
sudo touch /etc/gitlab/skip-auto-backupFixing errors during a failover or when promoting a secondary to a primary site
The following are possible error messages that might be encountered during failover or when promoting a secondary to a primary site with strategies to resolve them.
Message: ActiveRecord::RecordInvalid: Validation failed: Name has already been taken
When promoting a secondary site, you might encounter the following error message:
Running gitlab-rake geo:set_secondary_as_primary...
rake aborted!
ActiveRecord::RecordInvalid: Validation failed: Name has already been taken
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:236:in `block (3 levels) in <top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:221:in `block (2 levels) in <top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'
Tasks: TOP => geo:set_secondary_as_primary
(See full trace by running task with --trace)
You successfully promoted this node!If you encounter this message when running gitlab-rake geo:set_secondary_as_primary
or gitlab-ctl promote-to-primary-node, either:
-
Enter a Rails console and run:
Rails.application.load_tasks; nil Gitlab::Geo.expire_cache! Rake::Task['geo:set_secondary_as_primary'].invoke -
Upgrade to GitLab 12.6.3 or later if it is safe to do so. For example, if the failover was just a test. A caching-related bug was fixed.
Message: NoMethodError: undefined method `secondary?' for nil:NilClass
When promoting a secondary site, you might encounter the following error message:
sudo gitlab-rake geo:set_secondary_as_primary
rake aborted!
NoMethodError: undefined method `secondary?' for nil:NilClass
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:232:in `block (3 levels) in <top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:221:in `block (2 levels) in <top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'
Tasks: TOP => geo:set_secondary_as_primary
(See full trace by running task with --trace)This command is intended to be executed on a secondary site only, and this error message is displayed if you attempt to run this command on a primary site.
Expired artifacts
If you notice for some reason there are more artifacts on the Geo secondary site than on the Geo primary site, you can use the Rake task to cleanup orphan artifact files.
On a Geo secondary site, this command also cleans up all Geo registry record related to the orphan files on disk.
Fixing sign in errors
Message: The redirect URI included is not valid
If you are able to sign in to the web interface for the primary site, but you receive this error message when attempting to sign in to a secondary web interface, you should verify the Geo site's URL matches its external URL.
On the primary site:
- On the left sidebar, at the bottom, select Admin Area.
- Select Geo > Sites.
- Find the affected secondary site and select Edit.
- Ensure the URL field matches the value found in
/etc/gitlab/gitlab.rbinexternal_url "https://gitlab.example.com"on the Rails nodes of the secondary site.
Authenticating with SAML on the secondary site always lands on the primary site
This problem is usually encountered when upgrading to GitLab 15.1. To fix this problem, see configuring instance-wide SAML in Geo with Single Sign-On.
Fixing client errors
Authorization errors from LFS HTTP(S) client requests
You may have problems if you're running a version of Git LFS before 2.4.2.
As noted in this authentication issue,
requests redirected from the secondary to the primary site do not properly send the
Authorization header. This may result in either an infinite Authorization <-> Redirect
loop, or Authorization error messages.
Error: Net::ReadTimeout when pushing through SSH on a Geo secondary
When you push large repositories through SSH on a Geo secondary site, you may encounter a timeout. This is because Rails proxies the push to the primary and has a 60 second default timeout, as described in this Geo issue.
Current workarounds are:
- Push through HTTP instead, where Workhorse proxies the request to the primary (or redirects to the primary if Geo proxying is not enabled).
- Push directly to the primary.
Example log (gitlab-shell.log):
Failed to contact primary https://primary.domain.com/namespace/push_test.git\\nError: Net::ReadTimeout\",\"result\":null}" code=500 method=POST pid=5483 url="http://127.0.0.1:3000/api/v4/geo/proxy_git_push_ssh/push"Recovering from a partial failover
The partial failover to a secondary Geo site may be the result of a temporary/transient issue. Therefore, first attempt to run the promote command again.
-
SSH into every Sidekiq, PostgreSQL, Gitaly, and Rails node in the secondary site and run one of the following commands:
-
To promote the secondary site to primary:
sudo gitlab-ctl geo promote -
To promote the secondary site to primary without any further confirmation:
sudo gitlab-ctl geo promote --force
-
-
Verify you can connect to the newly-promoted primary site using the URL used previously for the secondary site.
-
If successful, the secondary site is now promoted to the primary site.
If the above steps are not successful, proceed through the next steps:
-
SSH to every Sidekiq, PostgreSQL, Gitaly and Rails node in the secondary site and perform the following operations:
-
Create a
/etc/gitlab/gitlab-cluster.jsonfile with the following content:{ "primary": true, "secondary": false } -
Reconfigure GitLab for the changes to take effect:
sudo gitlab-ctl reconfigure
-
-
Verify you can connect to the newly-promoted primary site using the URL used previously for the secondary site.
-
If successful, the secondary site is now promoted to the primary site.
Investigate causes of database replication lag
If the output of sudo gitlab-rake geo:status shows that Database replication lag remains significantly high over time, the primary node in database replication can be checked to determine the status of lag for
different parts of the database replication process. These values are known as write_lag, flush_lag, and replay_lag. For more information, see
the official PostgreSQL documentation.
Run the following command from the primary Geo node's database to provide relevant output:
gitlab-psql -xc 'SELECT write_lag,flush_lag,replay_lag FROM pg_stat_replication;'
-[ RECORD 1 ]---------------
write_lag | 00:00:00.072392
flush_lag | 00:00:00.108168
replay_lag | 00:00:00.108283If one or more of these values is significantly high, this could indicate a problem and should be investigated further. When determining the cause, consider that:
-
write_lagindicates the time since when WAL bytes have been sent by the primary, then received to the secondary, but not yet flushed or applied. - A high
write_lagvalue may indicate degraded network performance or insufficient network speed between the primary and secondary nodes. - A high
flush_lagvalue may indicate degraded or sub-optimal disk I/O performance with the secondary node's storage device. - A high
replay_lagvalue may indicate long running transactions in PostgreSQL, or the saturation of a needed resource like the CPU. - The difference in time between
write_lagandflush_lagindicates that WAL bytes have been sent to the underlying storage system, but it has not reported that they were flushed. This data is most likely not fully written to a persistent storage, and likely held in some kind of volatile write cache. - The difference between
flush_lagandreplay_lagindicates WAL bytes that have been successfully persisted to storage, but could not be replayed by the database system.
Resetting Geo secondary site replication
If you get a secondary site in a broken state and want to reset the replication state, to start again from scratch, there are a few steps that can help you:
-
Stop Sidekiq and the Geo LogCursor.
It's possible to make Sidekiq stop gracefully, but making it stop getting new jobs and wait until the current jobs to finish processing.
You need to send a SIGTSTP kill signal for the first phase and them a SIGTERM when all jobs have finished. Otherwise just use the
gitlab-ctl stopcommands.gitlab-ctl status sidekiq # run: sidekiq: (pid 10180) <- this is the PID you will use kill -TSTP 10180 # change to the correct PID gitlab-ctl stop sidekiq gitlab-ctl stop geo-logcursorYou can watch the Sidekiq logs to know when Sidekiq jobs processing has finished:
gitlab-ctl tail sidekiq -
Rename repository storage folders and create new ones. If you are not concerned about possible orphaned directories and files, you can skip this step.
mv /var/opt/gitlab/git-data/repositories /var/opt/gitlab/git-data/repositories.old mkdir -p /var/opt/gitlab/git-data/repositories chown git:git /var/opt/gitlab/git-data/repositoriesNOTE: You may want to remove the
/var/opt/gitlab/git-data/repositories.oldin the future as soon as you confirmed that you don't need it anymore, to save disk space. -
Optional. Rename other data folders and create new ones.
WARNING: You may still have files on the secondary site that have been removed from the primary site, but this removal has not been reflected. If you skip this step, these files are not removed from the Geo secondary site.
Any uploaded content (like file attachments, avatars, or LFS objects) is stored in a subfolder in one of these paths:
/var/opt/gitlab/gitlab-rails/shared/var/opt/gitlab/gitlab-rails/uploads
To rename all of them:
gitlab-ctl stop mv /var/opt/gitlab/gitlab-rails/shared /var/opt/gitlab/gitlab-rails/shared.old mkdir -p /var/opt/gitlab/gitlab-rails/shared mv /var/opt/gitlab/gitlab-rails/uploads /var/opt/gitlab/gitlab-rails/uploads.old mkdir -p /var/opt/gitlab/gitlab-rails/uploads gitlab-ctl start postgresql gitlab-ctl start geo-postgresqlReconfigure to recreate the folders and make sure permissions and ownership are correct:
gitlab-ctl reconfigure -
Reset the Tracking Database.
WARNING: If you skipped the optional step 3, be sure both
geo-postgresqlandpostgresqlservices are running.gitlab-rake db:drop:geo DISABLE_DATABASE_ENVIRONMENT_CHECK=1 # on a secondary app node gitlab-ctl reconfigure # on the tracking database node gitlab-rake db:migrate:geo # on a secondary app node -
Restart previously stopped services.
gitlab-ctl start