AI Architecture
GitLab has created a common set of tools to support our product groups and their utilization of AI. Our goals with this common architecture are:
- Increase the velocity of feature teams by providing a set of high quality, ready to use tools
- Ability to switch underlying technologies quickly and easily
AI is moving very quickly, and we need to be able to keep pace with changes in the area. We have built an abstraction layer to do this, allowing us to take a more "pluggable" approach to the underlying models, data stores, and other technologies.
The following diagram from the architecture blueprint shows a simplified view of how the different components in GitLab interact. The abstraction layer helps avoid code duplication within the REST APIs.
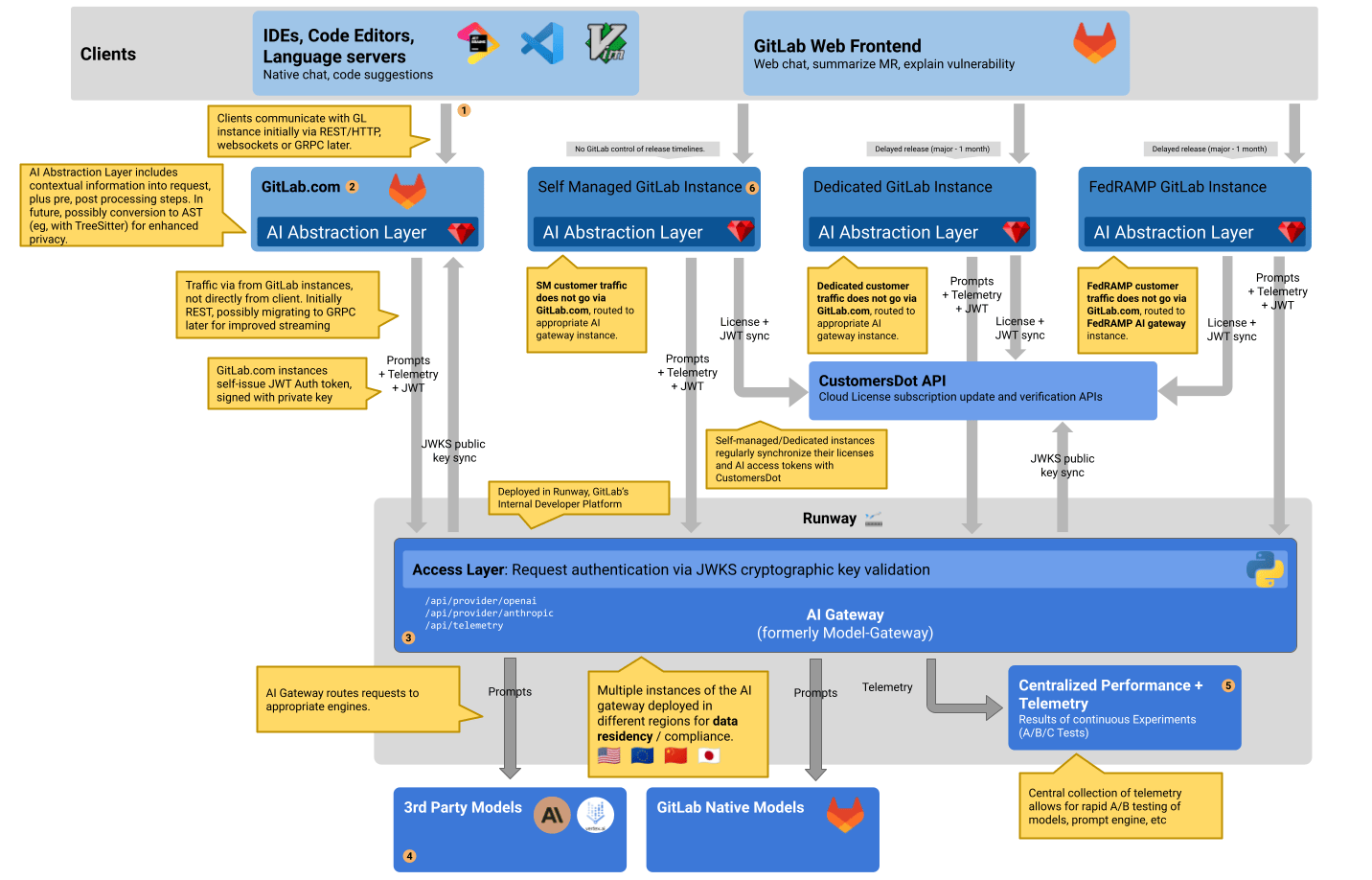
SaaS-based AI abstraction layer
GitLab currently operates a cloud-hosted AI architecture. We will allow access to it for licensed self managed instances using the AI-gateway. See the blueprint for details.
There are two primary reasons for this: the best AI models are cloud-based as they often depend on specialized hardware designed for this purpose, and operating self-managed infrastructure capable of AI at-scale and with appropriate performance is a significant undertaking. We are actively tracking self-managed customers interested in AI.
AI Gateway
The AI Gateway (formerly the model gateway) is a standalone-service that will give access to AI features to all users of GitLab, no matter which instance they are using: self-managed, dedicated or GitLab.com. The SaaS-based AI abstraction layer will transition to connecting to this gateway, rather than accessing cloud-based providers directly.
Calls to the AI-gateway from GitLab-rails can be made using the Abstraction Layer. By default, these actions are performed asynchronously via a Sidekiq job to prevent long-running requests in Puma. It should be used for non-latency sensitive actions due to the added latency by Sidekiq.
At the time of writing, the Abstraction Layer still directly calls the AI providers. Epic 11484 proposes to change this.
When a certain action is latency sensitive, we can decide to call the
AI-gateway directly. This avoids the latency added by Sidekiq.
We already do this for code_suggestions
which get handled by API endpoints nested in
/api/v4/code_suggestions. For any new endpoints added, we should
nest them within the /api/v4/ai_assisted namespace. Doing this will
automatically route the requests on GitLab.com to the ai-assisted
fleet for GitLab.com, isolating the workload from the regular API and
making it easier to scale if needed.
Supported technologies
As part of the AI working group, we have been investigating various technologies and vetting them. Below is a list of the tools which have been reviewed and already approved for use within the GitLab application.
It is possible to utilize other models or technologies, however they will need to go through a review process prior to use. Use the AI Project Proposal template as part of your idea and include the new tools required to support it.
Models
The following models have been approved for use:
- Google's Vertex AI and model garden
- Anthropic models
- Suggested reviewer
Vector stores
The following vector stores have been approved for use:
-
pgvectoris a Postgres extension adding support for storing vector embeddings and calculating ANN (approximate nearest neighbor).
Indexing Update
We are currently using sequential scan, which provides perfect recall. We are considering adding an index if we can ensure that it still produces accurate results, as noted in the pgvector indexing documentation.
Given that the table contains thousands of entries, indexing with these updated settings would likely improve search speed while maintaining high accuracy. However, more testing may be needed to verify the optimal configuration for this dataset size before deploying to production.
A draft MR has been created to update the index.
The index function has been updated to improve search quality. This was tested locally by setting the ivfflat.probes value to 10 with the following SQL command:
::Embedding::Vertex::GitlabDocumentation.connection.execute("SET ivfflat.probes = 10")Setting the probes value for indexing improves results, as per the neighbor documentation.
For optimal probes and lists values:
- Use
listsequal torows / 1000for tables with up to 1 million rows andsqrt(rows)for larger datasets. - For
probesstart withlists / 10for tables up to 1 million rows andsqrt(lists)for larger datasets.
Code Suggestions
Code Suggestions is being integrated as part of the GitLab-Rails repository which will unify the architectures between Code Suggestions and AI features that use the abstraction layer, along with offering self-managed support for the other AI features.
The following table documents functionality that Code Suggestions offers today, and what those changes will look like as part of the unification:
| Topic | Details | Where this happens today | Where this will happen going forward |
|---|---|---|---|
| Request processing | |||
| Receives requests from IDEs (VS Code, GitLab WebIDE, MS Visual Studio, IntelliJ, JetBrains, VIM, Emacs, Sublime), including code before and after the cursor | GitLab Rails | GitLab Rails | |
| Authenticates the current user, verifies they are authorized to use Code Suggestions for this project | GitLab Rails + AI Gateway | GitLab Rails + AI Gateway | |
| Preprocesses the request to add context, such as including imports via TreeSitter | AI Gateway | Undecided | |
| Routes the request to the AI Provider | AI Gateway | AI Gateway | |
| Returns the response to the IDE | GitLab Rails | GitLab Rails | |
| Logs the request, including timestamp, response time, model, etc | Both | Both | |
| Telemetry | |||
| User acceptance or rejection in the IDE | AI Gateway | Both | |
| Number of unique users per day | GitLab Rails, AI gateway | Undecided | |
| Error rate, model usage, response time, IDE usage | AI Gateway | Both | |
| Suggestions per language | AI Gateway | Both | |
| Monitoring | Both | Both | |
| Model Routing | |||
| Currently we are not using this functionality, but Code Suggestions is able to support routing to multiple models based on a percentage of traffic | AI Gateway | Both | |
| Internal Models | |||
| Currently unmaintained, the ability to run models in our own instance, running them inside Triton, and routing requests to our own models | AI Gateway | AI Gateway |
Self-managed support
Code Suggestions for self-managed users was introduced as part of the Cloud Connector MVC.
For more information on the technical solution for this project see the Cloud Connector MVC documentation.
The intention is to evolve this solution to service other AI features under the Cloud Connector product umbrella.
Code Suggestions Latency
Code Suggestions acceptance rates are highly sensitive to latency. While writing code with an AI assistant, a user will pause only for a short duration before continuing on with manually typing out a block of code. As soon as the user has pressed a subsequent keypress, the existing suggestion will be invalidated and a new request will need to be issued to the Code Suggestions endpoint. In turn, this request will also be highly sensitive to latency.
In a worst case with sufficient latency, the IDE could be issuing a string of requests, each of which is then ignored as the user proceeds without waiting for the response. This adds no value for the user, while still putting load on our services.
See our discussions here around how we plan to iterate on latency for this feature.